I'm Johann Wah, co-founder of Nika. This is my second article in my Geospatial Machine Learning Series, where I explain concepts and applying Machine Learning techniques into geospatial workflows. Click here the first article in this series.
Optimization Fundamentals First
Before diving into advanced techniques, let's nail down the basics. When configuring your model, batch size optimization is absolutely critical. You need to find that sweet spot by pushing right up to (but not exceeding) your memory limits. You can monitor your RAM percentage in real-time to find this threshold for your specific hardware.
For worker configuration on single GPU setups, we've consistently found that a 1:4 ratio delivers optimal performance. This balances processing efficiency without creating pipeline bottlenecks:
# Optimal configuration for most single GPU setups batch_size = 4 # Adjust based on your hardware num_workers = 4 # Consistent performance for quad-core systems
Traditional Shuffling: A Solid Starting Point
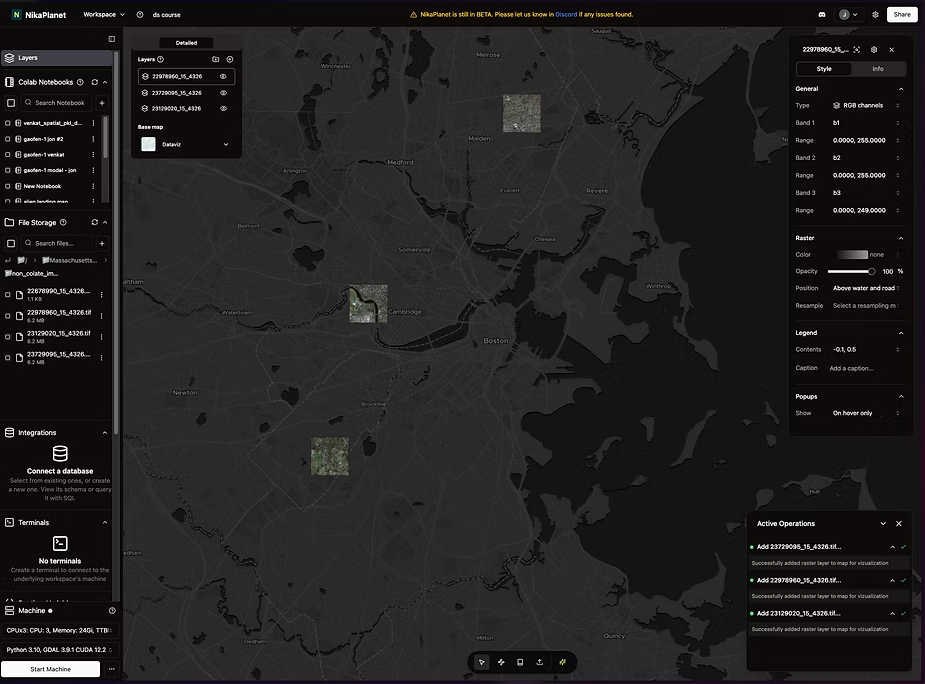
Example of what randomised data that has been shuffled may look like visualised.
All the images in this article showing the techniques are done in NikaPlanet, though the same principles can be applied in your GIS software of choice.
Most practitioners already implement proper data shuffling for randomization during training. This creates a solid baseline, distributing your imagery samples across different regions, lighting conditions, and feature types:
train_loader = DataLoader( dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers )
While shuffling works well initially, I've discovered it often falls short with large, diverse geospatial datasets spanning multiple regions and atmospheric conditions.
The Game-Changer: Spatial Batching
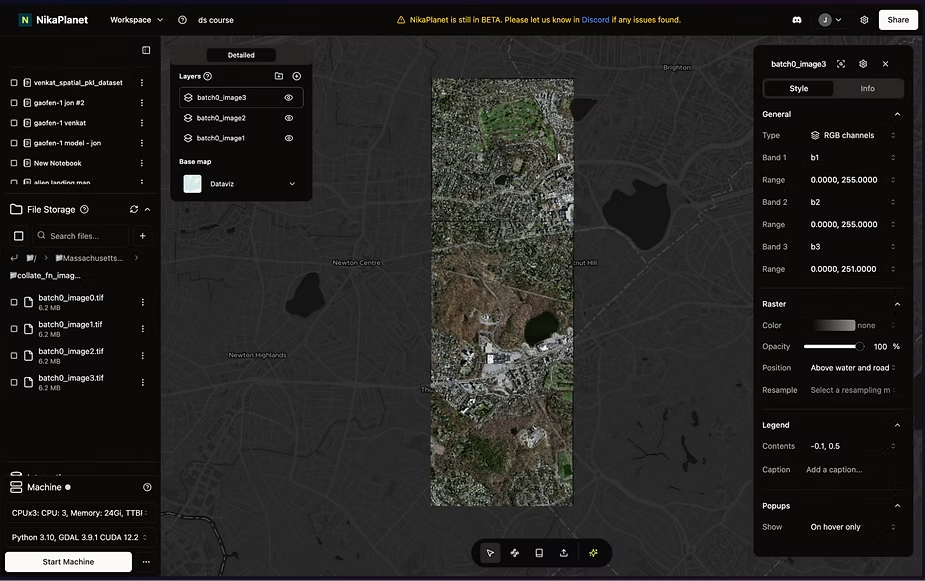
Example of what spatial batching looks like with the images within proximity of each other.
This is where spatial batching enters the picture. Instead of randomly selecting images, this technique deliberately groups images with spatial relationships together during the training process.
class SpatialBatchSampler(Sampler):
def _init_(self, file_paths, batch_size=4, distance_threshold_km=5.0):
self.file_paths = file_paths
self.batch_size = batch_size
self.distance_threshold_km = distance_threshold_km
self.locations = self._load_lat_lon()
self.batches = self._create_batches()
def _load_lat_lon(self):
"""Extract (lat, lon) for each file."""
locations = []
for path in self.file_paths:
with open(path, 'rb') as f:
data = pickle.load(f)
lat = data.get('lat_lon', {}).get('lat')
lon = data.get('lat_lon', {}).get('lon')
if lat is None or lon is None:
raise ValueError(f"Missing lat/lon in {path}")
locations.append((lat, lon))
return np.array(locations)
.......
def create_dataloaders_spatial(n_classes=2, batch_size=4, distance_threshold_km=5.0):
dataset = SatDataset(n_classes=n_classes, train=True)
sampler = SpatialBatchSampler(
file_paths=dataset.file_paths,
batch_size=batch_size,
distance_threshold_km=distance_threshold_km
)
loader = DataLoader(
dataset=dataset,
batch_sampler=sampler,
num_workers=4,
collate_fn=custom_collate_fn
)
return loader
The above is a sample code for spatial batching.
The key insight: Nearby satellite images share critical contextual information that random shuffling misses entirely. By maintaining these spatial relationships during training, your model gains access to consistent environmental contexts that dramatically improve recognition accuracy.
Visual comparison makes this clear: While traditional shuffling creates scattered batches across your study area, spatial batching creates coherent groups that preserve geographical context.
This simple adjustment has consistently pushed our accuracy from the 85% range up to 95% across diverse test regions.
Implementation Warning
A critical caution from my experience: While spatial batching delivers remarkable improvements, excessive application can lead to overfitting. Your model might perform brilliantly on training data but fail in real-world applications.
The solution is to implement proper cross-validation with geographically diverse holdout sets. This ensures your model generalizes effectively across regions rather than memorizing specific geographical patterns.
Ready-to-Implement Approach
For those looking to implement this in their workflows, here's my recommended approach:
- Establish a solid baseline with traditional shuffling
- Implement spatial batching with appropriate clustering parameters
- Monitor validation performance across geographically diverse holdout regions
- Adjust clustering intensity to balance accuracy gains against overfitting risks
If you're working with satellite imagery across diverse regions and still using standard shuffling techniques, you're leaving significant accuracy on the table. This technique has transformed our pipelines, and I'm confident it will do the same for yours.
The full spatial batching implementation code is available personally by sending me a LinkedIn message (Johann Wah) or to my co-founder, Lawrence Xiao. Mention "Spatial Batching" in the message and I'll send it to you directly.
📞 Interested for a 30-minute call with me instead? Schedule a call using the button below!